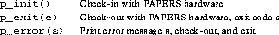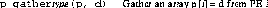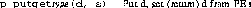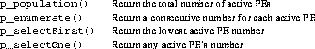 (
4K .ps.Z )
(
4K .ps.Z )
H. G. Dietz, T. M. Chung, T. Mattox, and T. Muhammad
School of Electrical Engineering
Purdue University
West Lafayette, IN 47907-1285
hankd@ecn.purdue.edu
January 1995
PAPERS, Purdue's Adapter for Parallel Execution and Rapid Synchronization, is an inexpensive little box that can be plugged into four or more PCs or workstations to support use of these machines as a single, dedicated, parallel computer. Conventional clusters link UNIX-based workstations using a socket protocol over a local area network (LANs like Ethernet, FDDI, ATM, or HiPPI); this can yield substantial bandwidth, but cannot provide the low latency required for fine-grain parallel computation. Further, the block- oriented point-to-point operations provided by a LAN are not a good match for the aggregate communications commonly found in data parallel programs.
A PAPERS cluster consists of a PAPERS unit and a group of four or more unmodified PCs or workstations. Interactions between processors are accomplished by UNIX user processes directly accessing the PAPERS hardware through a standard parallel printer port; this limits the bandwidth somewhat, but bypasses the operating system and thus provides latencies as low as a few microseconds, including all hardware and software overheads. A typical PAPERS cluster can perform a barrier synchronization, a 4-bit global OR, or any of a variety of other aggregate operations, in just a few microseconds -- no matter how many processors are in the cluster. Consequently, a PAPERS cluster can efficiently support fine-grain execution using a MIMD, SIMD, or VLIW model. Further, the PAPERS hardware design and support software is fully public domain, and PAPERS systems can be built easily and cheaply using standard components.
This paper details the PAPERS library for use with GCC.
The development of PAPERS was funded in part by Office of Naval Research (ONR) grant number N00014-91-J-4013. Facilities for the physical construction of the PAPERS prototypes were provided in part by National Science Foundation (NSF) award number CDA-9015696.
The HTML version of this paper differs from the standard
postscript version (click here
for the postscript version) in several
ways, including a variety of minor formatting changes. The
standard postscript version was formatted by groff
-mgs as a single file. In contrast, this HTML
document was generated using a script that replaces figures
with in-line gif images that are hypertext
linked to full-resolution postscript versions; the
(nK .ps.Z) at the upper
right of each in-line image provides both the size of the
compressed postscript file and the hypertext link. There
are also a variety of hypertext links inserted for
navigation within the document, including a Hypertext Index
at the end of this document (click here to jump to the Hypertext
Index).
PAPERS, Purdue's Adapter for Parallel Execution and Rapid Synchronizations, is designed to provide very low latency barrier synchronization and aggregate communication operations. Thus, the overriding concern in design and implementation of a public domain PAPERS support library has been to provide the most complete and useful library, while avoiding the usual software interface layering and the associated increases in latency. For this reason, the PAPERS library is based on the functionality of a very fine grain, proven effective, library: the library that supports MPL (a SIMD-parallel dialect of Gnu C) on MasPar's SIMD ( SIMD refers to Single Instruction stream, Multiple Data stream; i.e., a single processor with multiple function units organized so that the same operation can be performed simultaneously on multiple data values. ) supercomputers.
The reason that the PAPERS library isn't compliant with emerging standards for message-passing libraries (e.g., PVM or MPI) is simply that the basic structure of PAPERS operations is not an message-passing model. While interactions between PEs using message-passing systems are generally asynchronous and are always initiated by individual PEs, the PAPERS operations -- and supporting library routines -- are aggregate operations which are requested and performed in unison by all PEs (or all PEs within a specified group). Thus, although a PAPERS cluster is not restricted to SIMD execution, all PAPERS operations are based on a model of aggregate interaction that closely resembles SIMD communication. This isn't an accident; years of research involving Purdue University's PASM (PArtitionable Simd Mimd) prototype supercomputer have experimentally demonstrated that a SIMD-like interaction is more efficient than traditional message-passing for a wide range of applications.
The basic model for parallel computation using the PAPERS library with GCC is outlined in Section 2. Section 3 provides an overview of how the library is organized. Each of Sections 4 through 11 describes the functionality, use, and implementation algorithms of a group of related functions. Most are accompanied by measured performance for the TTL_PAPERS implementation [DiC95] . To minimize the TTL_PAPERS hardware (e.g., a 4 processor unit uses just 8 TTL chips), direct support for some operations had to be removed; thus, the times quoted for the PAPERS library using TTL_PAPERS generally form the lower bound on PAPERS performance. Section 12 summarizes the contributions of this paper and directions for further research.
Since we have already mentioned that the functionality of the PAPERS library is based on the library that supports MPL on MasPar's SIMD supercomputers, it is natural to assume that our model for parallel computation is also based on SIMD execution semantics -- however, this is not the case. In fact, our execution model is based on the properties of the generalized barrier synchronization mechanism that we have been developing since [DiS88] .
In barrier MIMD execution, each processor executes independently until it wishes to synchronize with an arbitrary group of (one or more) other processors. The barrier synchronization is accomplished by each processor individually informing the barrier unit that it has arrived, and then waiting to be notified that all participating processors have arrived. Once the barrier synchronization has completed, execution of each processor is again completely independent. Thus, barrier MIMD execution may look SIMD, but is in fact purely MIMD.
Suppose that, instead of executing just a barrier wait, all participating processors may additionally perform a communication operation. Again, the individual processors can be executing completely different programs. In fact, each can even behave differently within the communication (e.g., one processor broadcasts while others recieve). However, unlike asynchronous message-passing, the role of each processor in a synchronization or communication operation must be determined by that processor. Processors are free to dynamically alter how they interact, but only by means that preserve the static qualities of the interactions. For example, the only way for processor A to get data from processor B is for B to know that some processor wants this data, and to act accordingly in aggregate with A.
This model is most like synchronous messsage-passing in concept, but is much more powerful because the data values obtained can be any of a wide range of functions of the data from all processors within the aggregate. For example, reductions, scans (parallel prefix operations), and various other functions yield performance comparable to or better than the cost of performing a simple permutation communication. In summary, the PAPERS library model is pure barrier MIMD, but, because it efficiently implements aggregate communication operations, it can efficiently simulate SIMD or VLIW execution modes at a very fine grain level. The apparent execution mode also can be changed simply by changing the way in which the aggregate communication library routines are called.
The PAPERS library discussed in this document is designed to provide all the basic components needed for writing real applications using the Gnu C Compiler. It is not the only PAPERS library, and it is still under construction in the sense that the underlying algorithms for some functions are being improved and there are still a variety of additions planned (e.g., both mirror and RAID file I/O routines are currently being developed).
Before reviewing each of the library routines, it is useful to review the way in which the library is structured. Although a typical user need not know where all the component pieces of the library come from, Section 3.1 provides an overview of which files define which functions. The PAPERS library routines directly handle a variety of different data types, so Section 3.2 describes what types are supported and how type information is incorporated into function names.
Although the PAPERS library incorporates many files, a casual user only needs to know about:
A more sophisticated user can choose to include declarations for only those portions of the library which are needed for each application. These files are:
Still more sophisticated users may wish to performance-tweak some support library functions for a particular target machine (there is currently no assembly language code in any of the .c files), or may want to write additional PAPERS support functions. The following source files are available for modifying and rebuilding the library:
Only intern.h and inline.h contain assembly code for the parallel port interface. Consequently, only these two files need to be modified if the PC/workstation hardware interface to the PAPERS unit is changed. However, switching from one version of PAPERS to another version may require changes throughout the entire library, because the aggregate operations implemented by hardware vary.
Of course, all these files are accompanied by a Makefile and a variety of simple test, demonstration, and benchmark programs.
Unlike most implementations of PVM or MPI, the PAPERS hardware and interface software does not have a significant set-up time; an operation on n units of data generally takes the same time as performing n single-unit data operations. This fact is clearly demonstrated by the benchmark data given in the following sections. Thus, there is no reason to pack/unpack blocks of data into a memory-based message buffer. It is actually more efficient to perform the PAPERS operations directly using processor registers, with one PAPERS operation performed for each datum being acted upon, because this saves the cost of having to read and write each datum to a local memory buffer. In fact, the time to transmit a datum from a processor register through some PAPERS units is comparable to the time taken for two local memory buffer accesses.
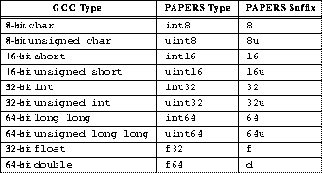
Thus, unlike PVM or MPI, the PAPERS library routines focus on low-latency communication operations that can act upon individual data values within a computation. Functions that return data values have multiple versions, one for each basic data type supported by the Gnu C Compiler (i.e., each type that could be held in a processor register). Each of these types is listed in Table 1, along with the equivalent portable type definition used in the PAPERS library (defined in the PAPERS types.h header file) and the function name suffix.
Table 1: PAPERS Data Types
The portable definition of these types yields a minor complication: if the machines within a cluster are not all based on the same processor, each may use a slightly different representation for the same value. In PVM, this is handled using the notoriously slow UNIX socket XDR (eXternal Data Representation) library routines to convert to a standard exchange format as values are moved into or out of the message buffer in local memory. However, the PAPERS unit is fed data in a way that is inherently insensitive to memory byte order; each datum is apparently sent directly from a processor register to a processor register. Thus, all integer data are inherently portable, and byte-order variations on floating point formats are also handled correctly. Currently, we assume that the floating point formats used on different machines do not differ by more than byte ordering -- an assumption that holds true for the vast majority of workstations. Later versions of the PAPERS library may handle more drastic floating point format variations by sending floating point values as separate exponent and mantissa, because these can be portably obtained and sent faster using PAPERS than the standard XDR routine could be applied.
A similar portability constraint arrises with respect to taking advantage of the fact that PAPERS may be able to operate faster on lower-precision values by transmitting only the specified number of bits. Although it might be possible to, for example, send only a portion of the mantissa of a floating point value, such operations are not portable. Thus, only functions that operate on unsigned integer values can be augmented by versions that have the ability to restrict the PAPERS operations to a specific number of bits. These functions are named with the suffix Bits followed by the suffix that specifies the unsigned integer type from which the low bits are extracted.
Before any program can use the PAPERS hardware, it must:
All of these functions are performed by simply calling p_init().
To indicate that a program has completed using PAPERS, it calls p_exit() with an argument which is used much like the argument to the ordinary UNIX exit() call. Notice, however, that calling p_exit() does not necessarily terminate the calling process -- it just terminates the use of PAPERS. The routine p_error() is provided to terminate the current PAPERS parallel program with the given error message.
At the lowest level of the PAPERS library, these routines form the interface for the most direct use of the PAPERS hardware.
To set the current barrier group, p_enqueue() is called with a bit mask that has a 1 bit in each position corresponding to a member of the barrier group. Currently, by default, all available processors are in the initial barrier group. To perform a barrier wait with the current barrier group, simply call p_wait().
The remaining three functions all operate on integer flags as single-bit truth values. The p_any() and p_all() operations are familiar enough to any user of parallel processing.
The p_waitvec() operation is actually a one-bit multibroadcast that allows all processors to obtain a mask vector constructed from the one-bit votes of all processors. Processor k's vote is in bit k of the result. Enabled processors vote 1 if f is true (non-zero), 0 otherwise. Disabled processors always vote 0. This voting operation was originally devised so that processors could vote on which partition they wanted to be in when a barrier group is divided by a parallel conditional, trivially creating the new barrier mask for each processor. However, it is also used to determine things like which processors want to access a shared resource, or which have extra work to do, etc. Thus, p_waitvec() is very commonly used, for example, by code generated by compilers or translators to schedule I/O operations; however, users are not expected to directly access this type of function.
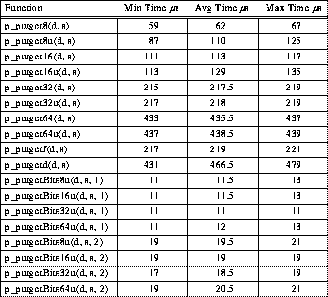
The PAPERS library gather operations collect a datum from each processor in the current barrier group, and fill-in the corresponding entries in each processor's local memory array whose address is passed as the first argument to the function. Array entries corresponding to processors that are not in the current barrier group are unaffected by the gather. Thus, a gather operation is essentially implemented by performing n broadcast operations, one from each of the n processors in the current barrier group. Because each processor in the group has a local copy of the barrier bit mask, no communication is needed to agree on which processor will broadcast when. The order is from the lowest-numbered enabled PE to the highest, determined independently by each processor shifting through its local copy of the barrier bit mask.
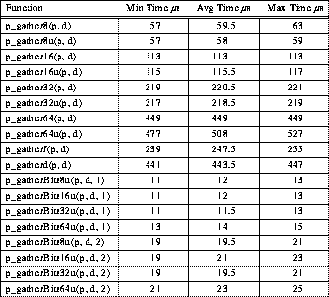
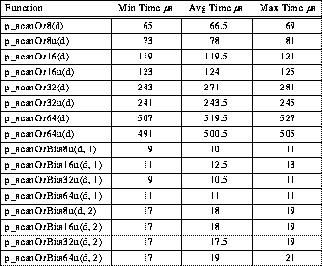
Another aspect of gather implementation that might not be obvious is how the TTL_PAPERS hardware implements a broadcast using only 4-bit NAND communication. The answer is simply that if n-1 one bits are NANDed together with a single variable bit, the result is always the complement of the variable bit. Thus, the PEs that are not broadcasting are actually sending TTL_PAPERS a value of 0xf, while the PE that is broadcasting sends the complement of its 4-bit datum. The performance of this implementation is summarized in Table 2.
Table 2: Typical 4-PE TTL_PAPERS Gather Timing
The PAPERS library putget operation is the most fundamental mechanism for supporting arbitrary communication between processors. The model is simply that each processor in the current barrier group outputs a datum, specifies which processor it wants the datum from, and returns the selected value. Logically, each processor writes to its own bus buffer within the PAPERS unit and simply snoops the value written on the bus it selects.
Although some versions of PAPERS directly implement this mechanism, TTL_PAPERS does not. Instead, it must map the putget into a series of simple broadcasts implemented by NANDing (as described in Section 6). There are two basic approaches to this mapping. One method is to simply force every processor in the barrier group to perform a broadcast; this is simple and consistent, but is innefficient for patterns in which the values sent by some processors are not used (i.e., this technique is best for permutations). The alternative is to first collect a vote from the processors as to which PEs would be sending useful values, and then to send only those values. Surprisingly, this voting operation is trivially accomplished for n processors using n/4 4-bit NAND operations to accumulate a vote bit vector in which a 1 bit corresponds to a processor that at least one PE wants the value from, and a 0 bit indicates that the corresponding PE need not send any data.
Table 3: Typical 4-PE TTL_PAPERS PutGet Timing
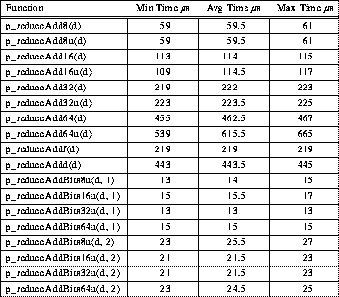
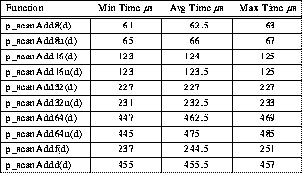
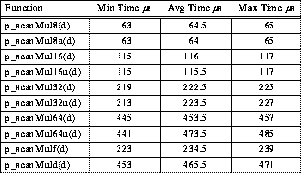
By definition, a reduction operation is an associative operation; i.e., the order in which the operations are performed does not significantly alter the resulting value. One way to perform these operations is to have all processors collect all the data and then serially reduce the local copy. This yields a very simple implementation suitable for clusters with up to about 8 processors, and actually most efficient for a typical 4-processor TTL_PAPERS cluster. For example, all the basic variations on p_reduceAdd can be implemented by:
#define REDUCEADD(name, type, suffix) \
type \
name(register type datum) \
{ \
type buf[NPROC]; \
buf[0] = (buf[1] = (buf[2] = (buf[3] = 0))); \
p_gather##suffix(&(buf[0]), datum); \
return(buf[0] + buf[1] + buf[2] + buf[3]); \
}
REDUCEADD(p_reduceAdd8, int8, 8)
REDUCEADD(p_reduceAdd8u, uint8, 8u)
REDUCEADD(p_reduceAdd16,int16, 16)
REDUCEADD(p_reduceAdd16u, uint16, 16u)
REDUCEADD(p_reduceAdd32,int32, 32)
REDUCEADD(p_reduceAdd32u, uint32, 32u)
REDUCEADD(p_reduceAdd64,int64, 64)
REDUCEADD(p_reduceAdd64u, uint64, 64u)
REDUCEADD(p_reduceAddf, f32, f)
REDUCEADD(p_reduceAddd, f64, d)
The problem with using this code on larger clusters is that it executes in O(n), rather than O(log2n), time for n processors. This is remedied by using the usual tree reduction with communication implemented by a p_putget operation for each of the log2n communication steps. However, the tree reduction is somewhat complicated by the fact that some processors might not be members of the current barrier group, in which case they do not participate in the reduction. Thus, if a tree reduction is to be used, the participating nodes must effectively be "renumbered" to determine their positions within the reduction tree. Fortunately, the renumbering can be computed without any communication operations -- each node is numbered by p_enumerate() and the tree contains p_population() leaves (see Section 11).
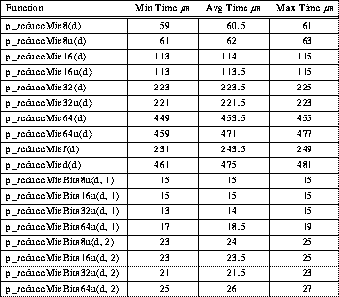
Table 4: Typical 4-PE TTL_PAPERS Addition Reduction Timing
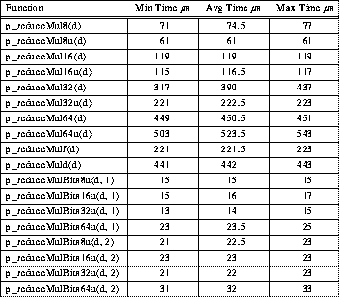
Table 5: Typical 4-PE TTL_PAPERS Multiplication Reduction Timing
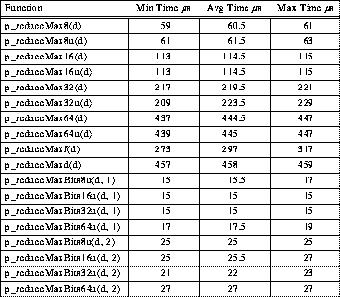
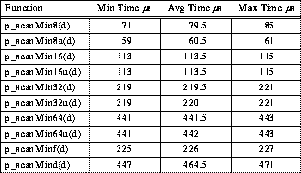
Table 6: Typical 4-PE TTL_PAPERS Minimum Reduction Timing
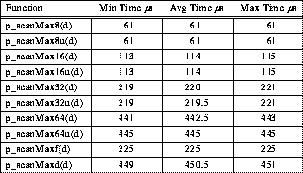
Table 7: Typical 4-PE TTL_PAPERS Maximum Reduction Timing
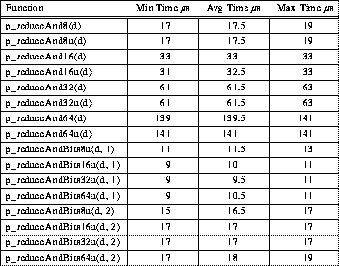
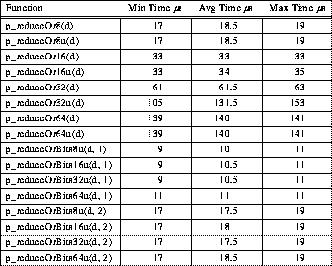
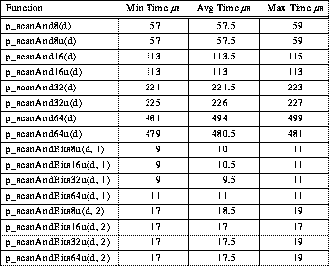
The TTL_PAPERS hardware communication mechanism is actually a 4-bit NAND of the data from all processors in the barrier group, which is accessed within the library by the in-line function p_nand(). Thus, a 4-bit bitwise OR can be implemented simply by complementing the inputs to the NAND. Likewise, a 4-bit bitwise AND is generated by complementing the result of a NAND.
Because bitwise operations are defined for each integer data type, there are eight different versions of each bitwise reduction operation. Fortunately, a 4*k-bit bitwise operation can be implemented by performing k 4-bit operations and using shifts to disassemble and reassemble the values. The use of shifts is important because it ensures that the resulting value is computed correctly even though some of the machines in the cluster may differ in the byte order that they use to store data in local memory.
For example, the following C code defines all eight different versions of p_reduceOr:
#define REDUCEOR(name, type, bitcnt) \
type \
name(register type datum) \
{ \
if (last_mask & ~OUR_MASK) { \
register int bits = (bitcnt - 4); \
\
/* Four bits at a time, or = nand not */ \
do { \
datum |= (p_nand((~(datum >> bits)) & 0xf) \
<< bits); \
} while ((bits -= 4) >= 0); \
} \
\
return(datum); \
}
REDUCEOR(p_reduceOr8, int8, 8)
REDUCEOR(p_reduceOr8u, uint8, 8)
REDUCEOR(p_reduceOr16, int16, 16)
REDUCEOR(p_reduceOr16u, uint16, 16)
REDUCEOR(p_reduceOr32, int32, 32)
REDUCEOR(p_reduceOr32u, uint32, 32)
REDUCEOR(p_reduceOr64, int64, 64)
REDUCEOR(p_reduceOr64u, uint64, 64)
Notice that the check involving OUR_MASK bypasses the entire communication if only this processor is in the current barrier group.
Additionally, each of the bitwise reductions has a "Bits" version for each of the unsigned integer data types. These are similar to the above, except in that each function takes a second argument which specifies the total number of bits to transmit.
Table 8: Typical 4-PE TTL_PAPERS Bitwise AND Reduction Timing
Table 9: Typical 4-PE TTL_PAPERS Bitwise OR Reduction Timing
A scan, or parallel prefix, computation is much like a reduction, but returns partial results to each of the processors. Like reductions, these operations can be performed in parallel or serially. For a small number of processors, using a gather operation to collect the data values in each processor and then serially computing the result for each processor in local memory works well, but there are many alternative implementations.
Aside from using a tree structured implementation (with the same barrier group numbering problem described for reductions in Section 9), many of the scan operations that use integer data can be implemented efficiently by methods based on 1-bit multibroadcasts. In some cases, the 1-bit multibroadcast would be used for processors to vote high or low relative to the value output by one processor (e.g., for a rank operation). For the Bits variants of the scans, a series of 1-bit multibroadcast operations can be used to transmit only the desired data bits from all processors.
Table 10: Typical 4-PE TTL_PAPERS Addition Scan Timing
Table 11: Typical 4-PE TTL_PAPERS Multiplication Scan Timing
Table 12: Typical 4-PE TTL_PAPERS Bitwise AND Scan Timing
Table 13: Typical 4-PE TTL_PAPERS Bitwise OR Scan Timing
Table 14: Typical 4-PE TTL_PAPERS Minimum Scan Timing
Table 15: Typical 4-PE TTL_PAPERS Maximum Scan Timing
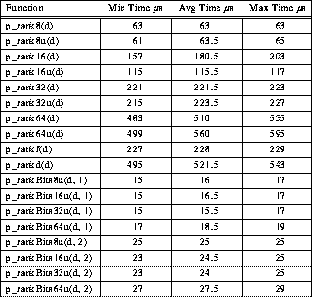
Table 16: Typical 4-PE TTL_PAPERS Rank Ordering Timing
It is sometimes necessary to determine basic properties of the set of processors in the current barrier group. These functions compute properties directly from the local copy of the current barrier bit mask, and hence need no communication.
The value of p_population() is literally the population count of (number of 1 bits within) the barrier bit mask. Some machines make this operation a single instruction. For other machines, it can be implemented using a table to count bits within each chunk of the mask (e.g., an 8-bit mask section can be counted using a 256-element table). For very large clusters, the population count can be computed using a log2n time for n bits "SIMD bit summation" within each processor (e.g., for 4 PEs, t=(mask&5)+((mask>>1)&5); population=(t>>2)+t;).
The value of p_enumerate() can be determined in essentially the same way, but before computing the bit population, the barrier mask should be bitwise ANDed with the current processor's bit mask minus 1. Thus, each processor counts the number of participating processors in the mask that have lower processor numbers than itself.
The remaining two operations are actually implemented by just one function in the current PAPERS library, which simply scans the current barrier bit mask for the lowest 1 bit and returns that position. Again, some machines have single instructions that can perform this type of operation very efficiently.
Table 17: Typical 4-PE TTL_PAPERS Group Counting Operation Timing
This paper has presented a brief, but complete, overview of how the PAPERS library is structured and how it performs using the minimum PAPERS hardware -- TTL_PAPERS using a four-processor cluster of 486DX 33MHz machines.
This library will continue to grow and mature, however, it does support most basic application program needs. Expect major changes very soon:
Please consider this document as a draft only; it will be either updated or replaced as changes are made.
![]() The only thing set in stone is our name.
The only thing set in stone is our name.